CVPR 2026 Submission
Cross-Sensory Inference
from Visual Cues
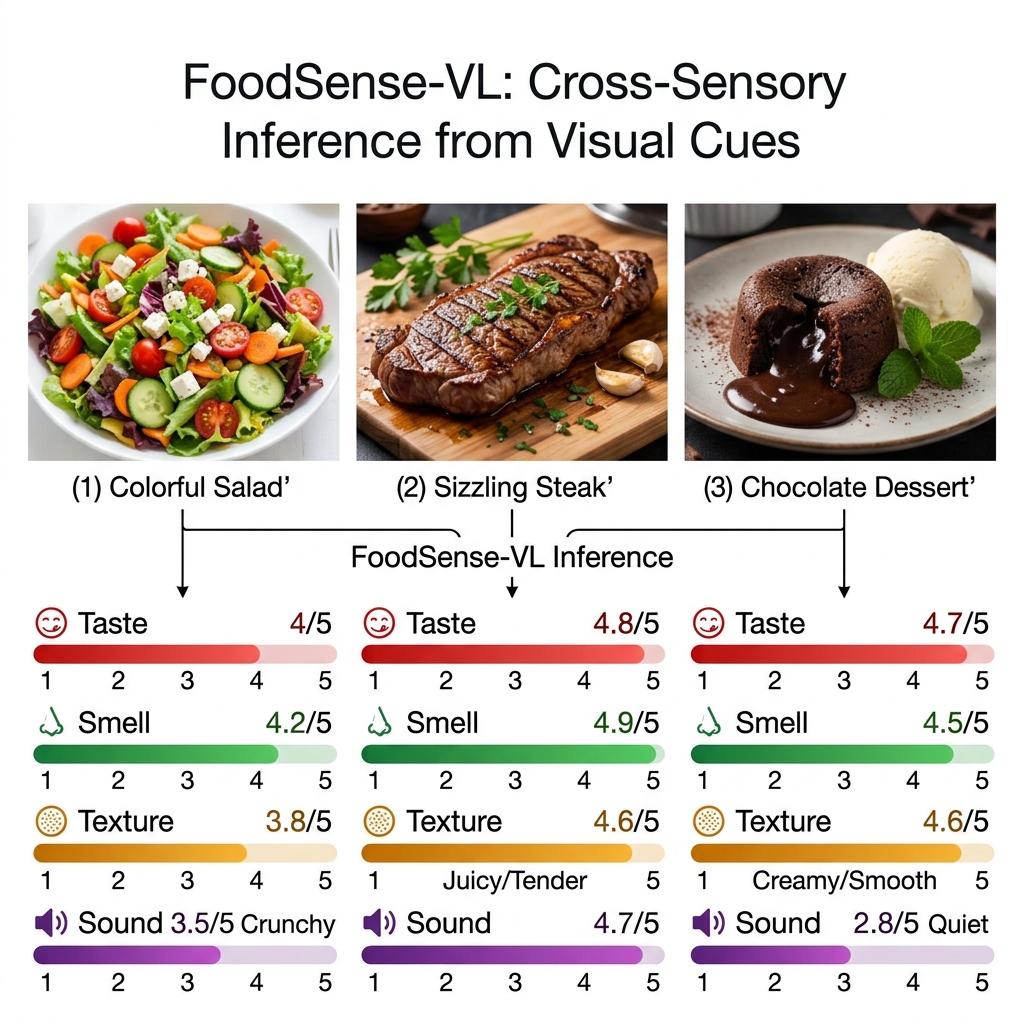
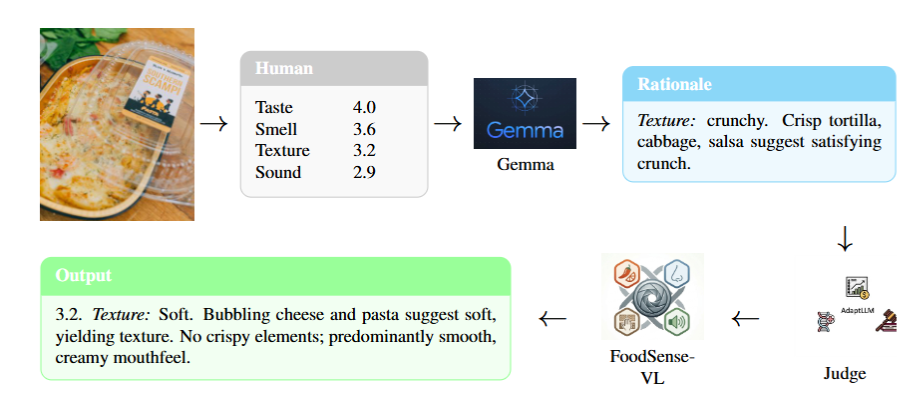
Predicting taste, smell, texture, and sound from food images. A human-annotated sensory benchmark and two-stage vision-language model for multisensory food understanding.
2,987
Annotated Food Images
66,842
Participant–Image Annotations
4
Sensory Modalities
6
Models Benchmarked